SSL (Secure Sockets Layer) es una tecnología de seguridad estándar para establecer un enlace encriptado entre un servidor y un cliente - típicamente un servidor Web y un navegador, o un servidor de correo y un cliente de correo (por ejemplo Outlook).
SSL permite que la información sensible como números de tarjeta de crédito, números de identificación y credenciales de autenticación puedan ser transmitidos de forma segura.
Normalmente los datos enviados entre los navegadores y los servidores Web son enviados en texto plano, dejando a estos vulnerables a ataques de espionaje. Si un atacante puede interceptar todos los datos que están siendo intercambiados entre un navegador y un servidor Web, el atacante puede ver y utilizar esa información.
Para ser más específicos hay que decir que SSL es un protocolo de seguridad. Los protocolos describen como los algoritmos deben ser usados; en este caso, el protocolo SSL determina las variables para hacer el cifrado del enlace y de los datos transmitidos.

Secure Socket Layer (SSL) se sitúa en la parte alta de la capa TCP, debajo de la capa de Aplicación y actúa como sockets conectados por conexiones TCP.
Es usado para dar seguridad a aplicaciones basadas en TCP (No UDP) o directamente sobre IP.
La aplicación mas popular en la que se utiliza SSL para dar seguridad a comunicaciones es HTTP sobre SSL ó HTTPS. Otras aplicaciones que podemos mencionar son SMTP/IMAP sobre SSL.

La conexión SSL se establece principalmente en dos fases, la fase de Handshake (Intercambio de saludo) y la fase de Transferencia Segura de Datos.
La fase de Handshake negocia los algoritmos criptográficos, autentica al servidor y establece llaves para el cifrado de los datos y los Mensajes de Autenticación de Código (MAC - Message Authentication Code).
La fase de Transferencia Segura de Datos envía datos cifrados sobre conexiones SSL establecidas.
La siguiente figura muestra como el flujo de mensajes durante la configuración de una conexión típica de SSL:

El cliente inicia una sesión enviando un mensaje Hello de cliente hacia el servidor. Este mensaje Hello contiene:
- Version: El cliente envía el numero de la versión SSL que soporta. Por ejemplo, para SSLv3 el número de versión es 3.0, para TLS el número de versión es 3.1
- Random: Esta es una estructura aleatoria generada por el cliente. Contiene la fecha y hora del cliente y un número de 26 bytes pseudo-randómico.
- Session ID (if any): Este campo es incluido si el cliente desea retomar una sesión previa. Si la longitud de este campo es 0 indica una nueva sesión.
- Cipher Suite: Esta es una lista de los conjuntos de cifrado que son soportados por el cliente. Un ejemplo de un conjunto de cifrado es TLS_RSA_WITH_DES_CBC_SHA, donde TLS es la versión del protocolo, RSA es el algoritmo que va a ser usado para un intercambio de llaves, DES_CBC es el algoritmo de cifrado y SHA es la función hash.
- Compression Methods: Actualmente no existen métodos de compresión soportados.

El servidor envía de regreso un mensaje en la versión mas alta que es soportada tanto por el Cliente como por el Servidor. Esta versión será usada durante la conexión. El servidor responde con su propio mensaje Hello. Este mensaje Hello contiene:
- Version: El servidor manda el número de versión mas alta soportada por ambos, cliente y servidor.
- Random: El servidor también genera su propio valor aleatorio. Este contiene su propia fecha y hora.
- Session ID: Si el cliente envía un ID de sesión vacío para iniciar una nueva sesión, el servidor genera un nuevo ID de sesión. Si el cliente manda un Session ID diferente de cero para retomar una sesión previa, el servidor usa el mismo Session ID enviado por el cliente. Si el servidor no puede retomar una sesión previa, entonces genera un nuevo Session ID.
- Cipher Suite: Esta es el conjunto de cifrado elegido por el servidor de la lista de conjuntos que fue propuesta por el cliente.
- Compression Method: Actualmente no hay métodos de compresión soportados.
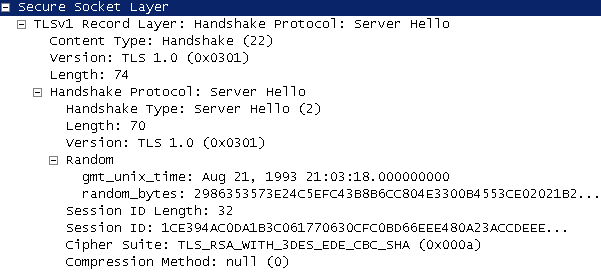
Luego de intercambiados los mensajes Hello, el cliente y el servidor generan un "secreto compartido autenticado", llamado pre_master secret el cual es convertido a master sercret. El SSLv3 y TLS soportan RSA y Diffie-Hellman para hacer el intercambio de llaves.
El servidor envía su certificado al cliente. El certificado del servidor contienen la Llave Pública del servidor. El cliente va a usar esta llave para autenticar el servidor y para cifrar el pre_master secret.

El pre_master secret tiene dos partes: La versión de protocolo del cliente y el número aleatorio. El pre_master secret es cifrado con la llave pública del servidor, obtenida del certificado que envió el servidor.
El servidor podría crear y enviar al cliente una llave Temporal usando un mensaje Server Key Exchange. Esta llave puede ser usada por el cliente para cifrar un mensaje Client Key Exchange. Este paso es requerido únicamente cuando el certificado del servidor no contiene una llave pública.
El servidor podría requerir la autenticación del cliente usando un mensaje Client Certificate Request .
El cliente responde con los mensajes Client Certificate y Client Certificate Verify . El mensaje Certificado de cliente (Client Certificate) contiene la llave pública del cliente y el mensaje de verificación del certificado del cliente (Client Certificate Verify) contiene el hash de todos los mensajes intercambiados hasta ese momento durante el Handshake firmados con la llave pública del cliente. Esto cumple el objetivo de autenticar al cliente.

Después de estos mensajes, el servidor envía un mensaje Server Hello Done indicando que el servidor ha terminado y que está esperando una respuesta desde el cliente.
Obtención de llaves
El cliente envía un mensaje Client Key Exchange después de haber procesado el pre_master secret. Este es cifrado con la llave pública del servidor y enviado de vuelta al servidor.En esta etapa el cliente y el servidor crean una llave maestra "master secret" individualmente a partir de los datos intercambiados en las fases previas.
La llave "Master secret" nunca es intercambiada.
El cliente y el servidor usan lo siguiente para generar la llave "Master secret":
- Pre_master secret
- Valores aleatorios de cliente y servidor

Entonces el cliente envía un mensaje Change Cipher Spec indicando al servidor que todos los mensajes que siguen al mensaje cifrando "terminado" (Encrypted Handshake) van a ser cifrados usando las llaves y algoritmos negociados.
El servidor manda también un mensaje Change Cipher Spec seguido por un mensaje Encrypted Handshake para indicar que el servidor va a comenzara cifrar los mensajes con las llaves negociadas.
Datos de aplicación
Después de la fase handshake, la comunicación comienza sobre la conexión SSL recientemente establecida.
El protocolo Record Protocol recibe los datos desde la capa de aplicación y es la responsable de la fragmentación de los datos en bloques y re-ensamblado de los bloques de datos, secuenciamiento de los bloques de datos, compresión/descompresión y cifrado/decifrado de los datos.

-----------------------------
Post tomado de (original post): http://www.networksbaseline.in/2016/01/secure-socket-layer-ssl-connection-setup.html
Traducido por José R. Torrico - Cisco Networking Academy Instructor